| МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
ФЕДЕРАЛЬНОЕ АГЕНТСТВО ПО ОБРАЗОВАНИЮ
ГОСУДАРСТВЕННОЕ ОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ
ВЫСШЕГО ПРОФЕССИОНАЛЬНОГО ОБРАЗОВАНИЯ
НОВОСИБИРСКИЙ ГОСУДАРСТВЕННЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
Кафедра Вычислительной Техники
Реферат
По дисциплине «Испытание и квалиметрия информационных систем»
на тему «Эффективность вейвлет фильтрации сигнала на GPGPU»
Факультет: АВТ
Группа: АММ-09
Студент: Е.Ю. Скоморохов
Проверил: Хайретдинов М.С., Пискунов С.В.
Новосибирск 2010
Содержание
Введение. 3
1 Вейвлет преобразование. 3
1.1 Организация модуля. 3
1.2 Фильтрация на CPU.. 3
1.3 Фильтрация на GPGPU.. 3
1.4 Проблемы распараллеливания. 3
1.5 Методы оптимизации. 3
Работа с памятью.. 3
Реорганизация вычислений. 3
1.6 Исследование производительности. 3
Заключение. 3
Список использованных источников. 3
Приложение А. Исходный код Вейвлет преобразования на GPGPU.. 3
dwt_kernel_float.cu — ядра GPGPU.. 3
dwt_float.cu — промежуточный слой между CPU и GPU слоями. 3
dwt_float.h — заголовочный файл с описание ядер и их параметров. 3
wavelet_denoise.cpp – общий ход Вейвлет преобразования. 3
Приложение Б. Характеристики сопроцессора на основе GPGPU.. 3
Приложение В. Запуск теста вейвлет преобразования. 3
Приложение Г. Калькулятор использования ресурсов устройства GPGPU.. 3
Введение
В численном и функциональном анализе дискретные вейвлет-преобразования (ДВП) относятся к вейвлет-преобразованиям, в которых вейвлеты представлены дискретными сигналами (выборками).
Первое ДВП было придумано венгерским математиком Альфредом Хааром. Для входного сигнала, представленного массивом 2n чисел, вейвлет-преобразование Хаара просто группирует элементы по 2 и образует от них суммы и разности. Группировка сумм проводится рекурсивно (в случае чётной длины последовательности сумм) для образования следующего уровня разложения. В итоге получается 2n−1 разность и 1 общая сумма.
Это простое ДВП иллюстрирует общие полезные свойства вейвлетов. Во-первых, преобразование (один уровень) можно выполнить за O(n) операций. Во-вторых, оно не только раскладывает сигнал на некоторое подобие частотных полос (путём анализа его в различных масштабах), но и представляет временную область, то есть моменты возникновения тех или иных частот в сигнале. Вместе эти свойства характеризуют быстрое вейвлет-преобразование — альтернативу обычному быстрому преобразованию Фурье.
Забиваем Сайты В ТОП КУВАЛДОЙ - Уникальные возможности от SeoHammer
Каждая ссылка анализируется по трем пакетам оценки: SEO, Трафик и SMM.
SeoHammer делает продвижение сайта прозрачным и простым занятием.
Ссылки, вечные ссылки, статьи, упоминания, пресс-релизы - используйте по максимуму потенциал SeoHammer для продвижения вашего сайта.
Что умеет делать SeoHammer
— Продвижение в один клик, интеллектуальный подбор запросов, покупка самых лучших ссылок с высокой степенью качества у лучших бирж ссылок.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз,
а первые результаты появляются уже в течение первых 7 дней.
Зарегистрироваться и Начать продвижение
Самый распространенный набор дискретных вейвлет-преобразований был сформулирован бельгийским математиком Ингрид Добеши (Ingrid Daubechies) в 1988 году. Он основан на использовании рекуррентных соотношений для вычисления всё более точных выборок неявно заданной функции материнского вейвлета с удвоением разрешения при переходе к следующему уровню (масштабу). В своей основополагающей работе Добеши выводит семейство вейвлетов, первый из которых является вейвлетом Хаара. С тех пор интерес к этой области быстро возрос, что привело к созданию многочисленных потомков исходного семейства вейвлетов Добеши.
В ходе данной работы запланировали достичь целей:
· повысить производительность, чтобы получить эффект интерактивности и при необходимости иметь возможность реализовать обработку в реальном времени;
· получить единые средства для вейвлет преобразования с любым ядром (Добеши, Хаара и другие);
· получить бесплатное средство обработки сигналов;
· проверить на практике эффективность GPGPU.
1 Вейвлет преобразование
Вейвлеты успешно применяются в задачах, связанных с обработкой информации, таких как очистка сигнала, от помех, сжатие данных, выявление кратковременных и глобальных закономерностей. В данной работе этот инструмент применяется для очистки сейсмического сигнала от шума.
Вейвлет-преобразование одномерного сигнала состоит в его разложении по базису, сконструированному из обладающей определенными свойствами солитоноподобной функции (вейвлета) посредством масштабных изменений и переносов. Каждая из функций этого базиса характеризует как определенную пространственную (временную) частоту, так и ее локализацию в физическом пространстве (времени).
Таким образом, в отличие от традиционно применяемого для анализа сигналов преобразования Фурье, вейвлет-преобразование обеспечивает двумерную развертку исследуемого одномерного сигнала, при этом частота и координата рассматриваются как независимые переменные. В результате, появляется возможность анализировать свойства сигнала одновременно в физическом (время-координата) и в частотном пространствах.
Интегральное вейвлет-преобразование записывается следующим образом:

где
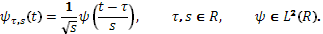
То есть базис функционального пространства  может быть построен с помощью непрерывных масштабных преобразований и переносов вейвлета может быть построен с помощью непрерывных масштабных преобразований и переносов вейвлета  с произвольными значениями базисных параметров – масштабного коэффициента s
и параметра сдвига с произвольными значениями базисных параметров – масштабного коэффициента s
и параметра сдвига  . .
Сервис онлайн-записи на собственном Telegram-боте
Попробуйте сервис онлайн-записи VisitTime на основе вашего собственного Telegram-бота:
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно.
Зарегистрироваться в сервисе
Выбор анализирующего вейвлета, как правило, определяется тем, какую информацию необходимо извлечь из сигнала. Каждый вейвлет имеет характерные особенности во времени и в частотном пространстве. При этом наиболее подходящими для аппроксимации сейсмических сигналов являются вейвлеты Добеши.
Формула материнского вейвлета задается следующим способом:
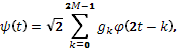
где
M
– целое число коэффициентов h,

Для дискретного вейвлет-преобразования Добеши 4-го порядка (при  ) коэффициенты hk
имеют следующие значения: h0
=0.48, h1
=0.84, h2
=0.22, h3
=-0.129 (рисунок 1). ) коэффициенты hk
имеют следующие значения: h0
=0.48, h1
=0.84, h2
=0.22, h3
=-0.129 (рисунок 1).
На рисунке 1 приведены вейвлеты семейства Добеши 2-го, 4-го, 5-го, 8-го и 10-го порядков. С повышением порядка (число нулевых моментов) повышается гладкость функций. Таким образом, подбором порядка материнского вейвлета можно добиться наилучшего приближения.

Рисунок 1 ‑ Семейство вейвлетов Добеши
Для шумоподавления возьмем вейвлет Добеши 8.
В качестве парадигмы шумоподавления была использована парадигма Донохо-Джонстона. Данная парадигма является достаточно простой для реализации, экономичной в вычислительном отношении, поскольку подразумевает использование лишь быстрых алгоритмов вейвлет-преобразования, и содержит три шага, которые, будучи последовательно примененные к исходному сигналу, создают эффект шумоподавления.
В частности, на первом шаге данной парадигмы отыскивается одно-двухуровневое или более глубокое разложение сигнала, затем, на втором шаге, к каждому из коэффициентов детализации уровня j
, а иногда коэффициентам аппроксимации того же уровня, применяется процедура трешолдинга, и, наконец, в заключении восстанавливается сигнал, характеризуемый, как ожидается, более высоким значением отношения сигнал/шум.
ДВП сигнала x
получают применением набора фильтров. Сначала сигнал пропускается через низкочастотный (low-pass) фильтр с импульсным откликом g
, и получается свёртка:
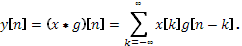
Одновременно сигнал раскладывается с помощью высокочастотного (high-pass) фильтра h
. В результате получаются детализирующие коэффициенты (после ВЧ-фильтра) и коэффициенты аппроксимации (после НЧ-фильтра). Эти два фильтра связаны между собой и называются квадратурными зеркальными фильтрами (QMF).
Так как половина частотного диапазона сигнала была отфильтрована, то, согласно теореме Котельникова, отсчёты сигналов можно проредить в 2 раза:

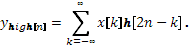
Однако каждый из получившихся сигналов представляет половину частотной полосы исходного сигнала, так что частотное разрешение удвоилось.
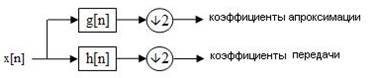
Рисунок 2 – Свертка и прореживание сигнала
Схема разложения сигнала в ДВП
С помощью оператора прореживания 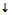
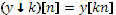
вышеупомянутые суммы можно записать короче:
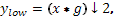
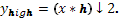
Каскадирование и банки фильтров.
Это разложение можно повторить несколько раз для дальнейшего увеличения частотного разрешения с дальнейшим прореживанием коэффициентов после НЧ и ВЧ-фильтрации. Это можно представить в виде двоичного дерева, где листья и узлы соответствуют пространствам с различной частотно-временной локализацией. Это дерево представляет структуру банка (гребёнки) фильтров.
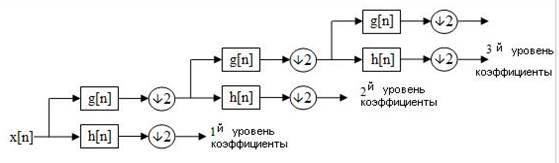
Рисунок 3 - Трехуровневый банк фильтров
На каждом уровне вышеприведённой диаграммы сигнал раскладывается на низкие и высокие частоты. В силу двукратного прореживания длина сигнала должна быть кратна 2n
, где n
— число уровней разложения.
Например, для сигнала из 32 отсчётов с частотным диапазоном от 0 до fn
трёхуровневое разложение даст 4 выходных сигнала в разных масштабах:
Таблица 1– Трехуровневое разложение сигнала размером в 32 отсчета
| Уровень
|
Частоты
|
Длина сигнала
|
| 3
|
0 … fn
/ 8
|
4
|
| fn
/ 8 … fn
/ 4
|
4
|
| 2
|
fn
/ 4 … fn
/ 2
|
8
|
| 1
|
fn
/ 2 … fn
|
16
|

Рисунок 4 - Представление ДВП в частотной области
Вейвлет-фильтрация состоит из следующих действий:
1. прямое дискретное вейвлет преобразование;
2. пороговая обработка коэффициентов, связанная с оценкой средних значений вейвлет коэффициентов на каждом из уровней разложения и последующим пороговым обнулением коэффициентов отражающих слабые импульсные свойства сигнала;
3. обратное вейвлет преобразование.
1.1 Организация модуля
На рисунке ниже приведем предполагаемую схему организации работы программы.

Рисунок 5 — Организация Вейвлет преобразования.
На рисунке 5 мы видим модуль основной программы, модуль библиотеки gsl, модуль, реализующий параллельное вейвлет преобразование.
Основная программа формирует сигнал, подготавливает материнский вейвлет с помощью модуля GSL и выполняет параллельное Вейвлет-преобразование с помощью модуля cudaDwt.
 Рисунок 6 – Ход вейвлет преобразования. Рисунок 6 – Ход вейвлет преобразования.
Исходя из целей, необходимо разработать модуль, который можно будет использовать без перекомпиляции на платформах одного типа и обладающий переносимостью на уровне компиляции при переносе с платформы на платформу (например, linux/Windows).
Опишем характеристики каждого из модулей:
Модуль CudaDwt
— исполняемая статическая/динамическая библиотека, переносимость на уровне исходных кодов между платформами ОС.
Модуль GSL
— свободно распространяемая библиотека для научных вычислений, переносимость на уровне исходных кодов между платформами ОС.
Требования:
CPU: intel-совместимый универсальный процессор не ниже i386.
GPU: NVIDIA видеокарта с поддержкой CUDA начиная с 8000-ой серии.
ОС: Windows XP и выше, Linux, Mac OS.
1.2 Фильтрация на CPU
Вейвлет преобразование выполняет свертку сигнала с фильтрами. Что и обуславливает длительную обработку при последовательной реализации.
Рассмотрим подробнее каждый из этапов.
Прямое преобразование
Выполняется сверка целевого сигнала с низкочастотным и высокочастотными фильтрами с одновременным прореживанием, что при последовательном выполнении дает трудоемкость кратную N/2.
Но так как данную операцию на исходной последовательности данных нужно проводить Log2
(N) раз, каждый раз уменьшая размерность на 2, то получаем трудоемкость:
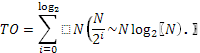
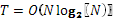
Трешолдинг
При пороговой обработке необходимо дважды пройти полученную свертку с низкочастотным и высокочастотными фильтрами и произвести отсечение по уровням. Таким образом, имеем трудоемкость:
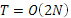
Обратное преобразование.
Обратное преобразование производится аналогично прямому и имеет ту же трудоемкость:
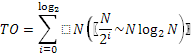
При использовании любых последовательных средств вычислений мы сталкиваемся с жесткой зависимостью от объема входных данных, выраженную в трудоемкости:
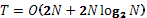
1.3 Фильтрация на
GPGPU
GPGPU – сопроцессор к центральному процессору для массово параллельных вычислений. Теоретически при использовании данного устройства для алгоритмов, допускающих мелкозернистый параллелизм, будет отсутствовать сильная связь с объемом входных данных. То есть при любом объеме мы будем получать результат за ограниченное время.
Перечислим возможности GPGPU как массивно параллельного устройства вычисления:
· множество процессоров виртуально может быть представлено в любой конфигурации с тремя с измерениями;
· каждый процессор имеет уникальный идентификатор;
· процессоры разделены на сильно связные компоненты – потоки в блоках, и слабосвязные – блоки в сетке;
· для оптимизации работы реализована иерархия памяти, технологии группового чтения данных, кэшированного чтения данных;
· одновременно можно запустить на выполнение множество тысяч потоков.
Представим каждую из трех частей в параллельном виде, доступном для запуска на массивно параллельном вычислителе.
Прямое вейвлет преобразование.
При прямом вейвлет преобразовании выполняется свертка и для каждого значения ряда сигнала вычисляется новое значение в соответствии с массивами коэффициентов.
Так как значение свертки для отсчета не зависит от вычисления других, то все вычисления можно распараллелить по номеру отсчета.
Поэтому всё что нужно, это, используя необходимые CUDA расширения языка Си, переписать исходный код последовательной реализации, убрать конструкцию цикла, и сделать вычисление адреса текущего элемента во входной последовательности через уникальные идентификаторы процессора потока.
Что и выполнено ниже:
__global__ void
cudaDWTStepForward(float *a, const size_t n, const size_t nmod, const size_t stride, const float * const h1, const float* const g1, const size_t nc, float*scratch)
{
const size_t idx = blockDim.x * blockIdx.x + tidx; // индекс элемента данных в первой половине = РазмерБлока*номерБлока + индексПотокаВБлоке
const size_t n1 = n - 1;
const size_t nh = n >> 1;
if(idx < nh){
float h = 0, g = 0;
const size_t ni = 2*idx + nmod;
for (size_t k = 0; k < nc; k++) // работа с коэффициентами
{
const size_t jf = n1 & (ni + k);
const float ani = a[stride * jf];
h += h1[k] * ani;
g += g1[k] * ani;
}
scratch[idx] += h; // Преобразованные данные
scratch[idx + nh] += g;
}
Также необходимо произвести расчет числа процессоров под задачу прямого преобразования исходя из формулы:
Число процессоров = числу входных элементов.
Вызов функции на выполнение:
// параметры конфигурации исполнения
const size_t block_size = BL_SZ;
dim3 threads( block_size, 1);
const size_t grid_size = (n/2) / (block_size - nc) + (((n/2)%(block_size - nc))>0); // n/2 потому проходится лишь первая половина
dim3 grid(grid_size, 1);
// запуск ядра на видео-карте
cudaDWTStepForward<<< grid, threads >>>(d_a, n, nmod/*, stride*/, d_h1, d_g1, nc, d_scratch);
Теоретическая трудоемкость данного кода будет приближаться к O(Log2(N)), так как необходимо последовательно выполнить данную функцию для прямого преобразования в соответствии с алгоритмом, описанном выше.
Пороговая обработка
При пороговой обработке мы получаем аналогичную ситуацию и для каждого элемента данных можно запустить свой поток обработки, что продемонстрировано ниже:
__global__ void
cudaDenoiseKernel(float *data, const size_t n,const float threshold)
{
const size_t idx = blockDim.x * blockIdx.x + threadIdx.x; // индекс элемента данных в первой половине = РазмерБлока*номерБлока + индексПотокаВБлоке
if(idx < n){
float d = data[idx];
const float fd = fabsf(d);
float t = fd - threshold;
t = (t + fabsf(t)) / 2.f;
// Signum
if (d != 0.f) d = d / fd * t;
data[idx] = d;
}
}
Для успешного выполнения обработки необходимо жестко контролировать нахождение алгоритма внутри допустимого множества вычисляемых данных. Контроль необходимо осуществлять как при проектировании ядра, так и во время вычисления количества и конфигурации потоков для запуска ядер:
// параметры конфигурации исполнения
const size_t block_size = 16;
dim3 threads( block_size, 1);
const size_t grid_size = len / (block_size) + ((len%(block_size))>0); // n/2 потому проходится лишь первая половина
dim3 grid(grid_size, 1);
// запуск ядра на видео-карте
cudaDenoiseKernel<<< grid, threads >>>(d_a, len, threshold);
Обратное вейвлет преобразование.
Обратное вейвлет преобразование мало отличается от прямого, разве что формулой вычисления.
Также для каждого входного элемента можно создать отдельный поток.
Рассмотренные выше методы распараллеливания довольно тривиальны и очевидны, но, к сожалению, использование только лишь здравого смысла как показывает практика - не дает роста производительности по сравнению с реализацией на универсальном вычислительном устройстве. А дает лишь набор проблем при работе с модулем и неточности результатов.
1.4 Проблемы распараллеливания
При распараллеливании задачи в лоб, без использования дополнительных знаний архитектуры и методов разработки под массивно параллельный вычислители сложно получить эффективную программу.
Приведем проблемы, которые необходимо преодолеть для получения эффективной программы.
· Проблема точности вычислений: GPGPU имеют короткую историю и фактически начали активно развиваться лишь с 2007-го года: в настоящее время поддержка плавающих чисел двойной точности всё еще является предметом обсуждения и встроена не во все имеющиеся GPGPU; также следует отметить потерю производительности при использовании плавающих чисел двойной точности.
· Проблема балансировки загрузки памяти, процессоров, шин памяти для эффективного использования устройства – что в конечном итоге сказывается на производительности.
· Необходимо детальное изучение аппаратных возможностей массивно параллельных устройств вычислений, для использования их технологий, без которых невозможно достижение искомой эффективности.
· После проведенных работ по оптимизации поддержка кода становится невозможной.
1.5 Методы оптимизации
Глобальная память
Глобальная память (GPU DRAM) не кэшируется и поэтому одно обращение к ней может занимать до 600 тактов. Именно оптимизация работы с глобальной памятью может дать огромный прирост производительности.
Обращение к глобальной памяти осуществляется через чтение/запись 32/64/128-битовых слов.
__device__ type dev [32]; // 32 items of type in global memorytype data = dev [threadIdx.x]; // reading one item from global memory Для того, чтобы обращение в глобальную память было скомпилировано в одну команду, важно, чтобы sizeof(type)
был равен 4/8/16 байтам и расположение данных было выровнено по sizeof(type)
в памяти.
__device__ float data [256];float3 v; . . . . v = data [i]; Рассмотрим пример выше - размер float3
равен 12 байтам и, поэтому, многие элементы массива data
не будут надлежащим образом выровнены. Все это ведет к неэффективному обращению к глобальной памяти. Избежать этого можно несколькими способами.
Простейшим является замена float3
на float4
- хотя мы при этом будем использовать немного больше памяти, но размер каждого элемента массива будет равен 16 байтам и каждый элемент будет выровнен в памяти по 16 байтам. Это позволит скомпилировать каждое обращение к элементу такого массива в одну команду.
Точно такая же ситуация возникает при использовании структур. Если размер структуры превышает 16 байт, то будет произведено несколько обращений к памяти. Для наибольшей эффективности желательно, чтобы размер структуры был кратен 4/8/16 байтам и все экземпляры данной структуры были выровнены в памяти. Так приводимый ниже пример использует опцию __align__
для обеспечения выравнивания в памяти по 16 байтам (что позволит минимизировать число операций чтения/записи).
struct __align__(16){ float a; float b; float c;}; Вся память GPU, выделяемая при помощи различных запросов, всегда выровнена как минимум по 256 байтам.
Крайне важной особенностью GPU является возможность объединения (coalescing global memory accesses
) нескольких запросов к глобальной памяти в одну операцию над блоком (транзакцию). Подобное объединение запросов в один запрос чтения/записи одного блока длиной 32/64/128 байт может происходить в пределах одного half-warp
'а. Для того, чтобы такое объединение произошло, должны быть выполнены специальные требования на то, как отдельные нити half-warp
'а обращаются к памяти.
Адрес блока должен быть выровнен в памяти. Также должны быть выполнены дополнительные требования, зависящие от Compute Capability
GPU.
Для GPU с Compute Capability
1.0 и 1.1 объединения запросов в одну транзакцию будет происходит при выполнении следующих условий:
· нити должны обращаться либо к 32-битовым словам, давая при этом в результате один 64-байтовый блок (транзакцию), либо к 64-битовым словам, давая при этом один 128-байтовый блок (транзакцию);
· все 16 слов должны лежать в пределах данного блока (64 или 128 байт)
· нити должны обращаться к словам последовательно, т.е. k
-ая нить должна обращаться к k
-му слову (при этом допускается, что какие-то нити вообще не производят обращения к соответствующим им словам).
Если нити half-warp
'а не удовлетворяют какому-либо из данных условий, то каждое обращение к памяти происходит как отдельная транзакция. На следующих рисунках приводятся типичные паттерны обращения, дающие объединения и не дающие объединения.
 
Рисунок 7 - Паттерны обращения к памяти, дающие объединение для Compute Capability
1.0 и 1.1.
На рисунке 7 приведены типичные паттерны обращения к памяти, приводящие к объединению запросов в одну транзакцию. Слева у нас выполнены все условия, справа - просто для части нитей пропущено обращение к соответствующим словам (что равно позволяет добавить фиктивные обращения и свести к случаю слева).
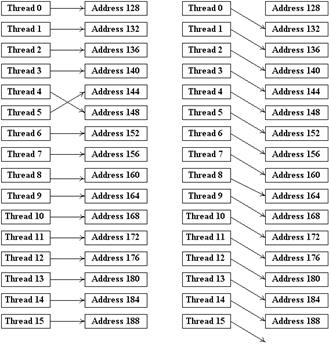
Рисунок 8 - Паттерны обращения к памяти, не дающие объединение для Compute Capability
1.0 и 1.1.
На рисунке 8 слева для нитей 4 и 5 нарушен порядок обращения к словам, а справа нарушено условие выравнивание - хотя слова, к которым идет обращения и образуют непрерывный блок из 64 байт, но начало этого блока (по адресу 132) не кратно его размеру.
Для GPU с Compute Capability
1.2 и выше объединения запросов в один будет происходить, если слова, к которым идет обращение нитей, лежат в одном сегменте размера 32 байта (если все нити обращаются к 8-битовым словам), 64 байта (если все нити обращаются к 16-битовым словам) и 128 байт (если все нити обращаются к 32-битовым или 64-битовым словам). Получающийся сегмент (блок) должен быть выровнен по 32/64/128 байтам.
Обратите внимание, что в этом случае порядок, в котором нити обращаются к словам, не играет никакой роли и ситуация на рисунке 8 слева приведет к объединению всех запросов в одну транзакцию.
Если идет обращения к n
соответствующим сегментам, то происходит группировка запросов в n
транзакций (только для GPU с Compute Capability
1.2 и выше).
Еще одним моментом работы с глобальной памятью является то, что гораздо эффективнее с точки зрения объединения запросов к памяти является использование не массивов структур, а структуры массивов (отдельных компонент исходной структуры).
struct A __align__(16){ float a; float b; uint c;}; A array [1024]; . . .A a = array [threadIdx.x]; В приведенном выше примере чтение структуры каждой нитью не даст объединения обращений к памяти и на доступ к каждому элементу массива A
понадобится отдельная транзакция.
Вместо одного массива A
можно сделать три массива его компонент.
float a [1024];float b [1024];uint c [1024];. . .float fa = a [threadIdx.x];float fb = b [threadIdx.x];uint uc = c [threadIdx.x]; В результате такого разбиения каждый из трех запросов к очередной компоненте исходной структуры приведет к объединению и в результате нам понадобится всего по три транзакции на half-warp
(вместо 16 ранее).
Еще одним важным моментом при работе с глобальной памятью является то, что при большом числе нитей, выполняемых на мультипроцессоре (мультипроцессор поддерживает до 768 нитей), время ожидания warp
'ом доступа к памяти может быть использовано для выполнения других warp
'ов. Чередование вычислений с обращениями к памяти позволяет более оптимально использовать ресурсы GPU.
Так первому warp
'у нужен доступ к памяти. Управление передается другому warp
'у, выполняется одна команда для него, далее управление опять передается следующему warp
'у и т.д. Для того, чтобы избежать "простоя" мультипроцессора, достаточно обеспечить большое количество warp
'ов, которые смогут выполняться в то время, когда первый warp
ждет.
Для оптимального доступа к памяти и регистрам желательно, чтобы количество нитей в блоке было кратным 64 и было не менее 192.
Работы с shared
-памятью
Для повышения пропускной способности вся shared
-память разбита на 16 банков. Каждый банк работает независимо и если идет обращение к набору слов, лежащих в разных банках, то все эти запросы будут обработаны одновременно.
Если же сразу несколько нитей обращаются к одному и тому же банку памяти, то происходит конфликт банков (bank conflict
) и эти запросы будут выполняться последовательно один за другим (т.е. в несколько раз медленнее).
Банки памяти организованы следующим образом - последовательно идущие 32-битовые слова попадают в последовательно идущие банки. GPU при обращении к shared
-памяти независимо обрабатывает запросы от нитей из первого и от второго half-warp
'ов. Таким образом, нити, принадлежащие разным half-warp
'ам не могут вызывать конфликт банков - конфликтовать могут только нити в пределах каждого half-warp
'а между собой.
Рассмотрим типичный пример, когда адрес для обращения к памяти линейно зависит от номера нити:
__shared__ float buf [128];float v = buf [baseIndex + threadIdx.x * s]; При такой схеме обращения к shared
-памяти конфликтов не будет только тогда, когда s
нечетно. Однако обратите внимание, что если идет доступ к элементам меньшего размера, то ситуация изменяется:
__shared__ char buf [128];char v = buf [baseIndex + threadIdx.x]; Как легко заметить buf[0]
, buf[1]
, buf[2]
и buf[3]
лежат в одном и том же банке. Поэтому в приведенном выше случае будет иметь место 4-кратный конфликт. Однако его легко можно избежать, поменяв схему обращения к памяти:
__shared__ char buf [128];char v = buf [baseIndex + threadIdx.x * 4]; На следующем рисунке приведены типичные способы обращения нитей к shared
-памяти, когда конфликтов банков не происходит - фактически это означает что существует взаимно-однозначное соответствие между нитями half-warp
'а и банками памяти.
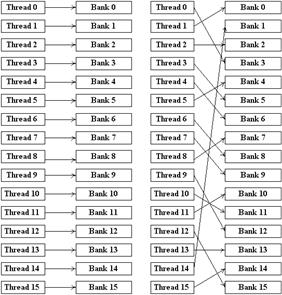
Рисунок 9 - Паттерны безконфликтного доступа к банкам shared
-памяти.
Возможен на самом деле еще один случай, когда конфликта банков не происходит - если все нити обращаются к одному и тому же адресу в памяти - в этом случае происходит всего одно обращение к памяти.
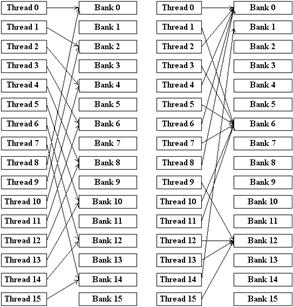
Рисунок 10 - Паттерны доступа, приводящие к конфликтам.
На рисунке 10 приведены два способа обращения к shared
-памяти, приводящие к возникновению конфликтов.
Довольно часто используемым приемом при работе с shared
-памятью является загрузка блока большой исходной матрицы в небольшую (обычно 16*16) матрицу в shared
-памяти и проведение расчетов, используя загруженную матрицу.
При этом сама загрузка (когда каждая нить загружает по одному элементу) обычно приводит к объединению запросов в глобальную память. Однако при обработке полученной небольшой матрицы в shared
-памяти следует иметь в виду, что если ее размер кратен 16, то каждый ее столбец размещается в одном банке. Поэтому если каждая нить по очереди перебирает элементы, сначала из первого столбца, затем из второго и т.д., то мы сразу получаем конфликт банков, причем порядка 16.
Самым простым способом избежать этого является дополнение матрицы еще одним столбцом (т.е. от матрицы из 16 столбцов мы переходим к матрице из 17 столбцов). За счет этого расположение столбцов в памяти сдвигается, и каждый столбец теперь равномерно распределяется по всем банкам памяти.

Рисунок 11 - Дополнение матрицы.
Вообще подобный прием - добавление к каждой строке матрицы нескольких дополнительных байт довольно распространен в CUDA - за счет него при доступе к глобальной памяти мы легко гарантируем выравнивание для начала строки, а при доступе к shared
-памяти - равномерное распределение столбца по банкам памяти.
Локальная память
Когда нитям блока не хватает имеющихся на мультипроцессоре регистров, то для размещения локальных переменных используется локальная память GPU. Локальная память размещена в DRAM и не кэшируется, поэтому доступ к ней такой же медленный как и к глобальной памяти. Однако компилятор выполняет запросы отдельных нитей к локальной памяти, объединяя в одну транзакцию (coalescing
).
Реорганизация вычислений
Как последнее и наиболее радикальное средство повышения производительности рассматривают – изменение принципов алгоритма и используемых функций вычислений.
Так для получения быстрых и удовлетворяющих вашим требованиям программ на CUDA нужно знать специфические команды архитектуры и их стоимость (число тактов, clocks
).
Рассмотрим специфические команды архитектуры. Выполнение следующих действий требует 4 тактов мультипроцессора:
· операции сложения, умножения и madd
для типа float
;
· целочисленное сложение;
· побитовые операции, сравнение, min
, max
;
· операции преобразования типов.
Функции 1/x
, 1/sqrt(x)
и __logf(x)
выполняются за 16 тактов.
Целочисленное умножение (32-битовое) также требует 16 тактов, однако во многих случаях вместо него можно воспользоваться функциями __mul24(x,y)
и __umul24(x,y)
, которые занимают всего 4 такта, но осуществляют 24-битовое умножение (т.е. если числа не очень большие - старший байт равен нулю - то эти функции точно заменяют умножение).
Крайне дорогостоящими операциями, которые желательно избегать, оказывается целочисленное деление (x/y
) и целочисленный остаток от деления (x%y
). В ряде случаев их можно заменять побитовыми операциями, в случае когда идет деление на константу (являющуюся степенью двух) или взятие остатка от деления на константу (вида 2n
-1
), то компилятор сам заменяет операцию на побитовую.
Квадратный корень реализуется как суперпозиция двух операций 1/x
и 1/sqrt(x)
и поэтому занимает 32 такта.
Деление на значение типа float
требует 36 тактов, однако есть функция __fdividef(x,y)
, осуществляющая деление за 20 тактов (но возвращающая ноль при очень больших значениях y
).
Функции __sinf(x)
, __cosf(x)
и __expf(x)
требуют 32 тактов, функции sinf(x)
, cosf(x)
, sincos(x)
и tanf(x)
гораздо более дорогостоящи.
Кроме того компилятор может вставлять команды для приведения типа в следующих случаях:
· на вход функции, принимающий int
(или usnigned int
) передается char
или short
;
· использование констант типа double
внутри выражения, использующего float
;
· передаче float
-значения на вход функции, требующей double
(например sin
).
Поэтому рекомендуется явно указывать тип float
, например вместо 1.3
писать 1.3f
и использовать float
-аналоги функций (например __sinf
или sinf
вместо sin
).
Обращение к памяти занимает 4 такта, при обращении к глобальной памяти следует также добавить еще от 400 до 600 тактов.
Вызов __syncthreads()
требует 4 тактов, если не нужно ждать ни одной нити в warp
'е.
Но следует отметить, что данный этап обычно требует изменений алгоритма, введений новых ограничений на размеры чисел и других особенностей, которые в итоге приводят к громоздкому и совершенно неадекватному при модификациях коду.
Как альтернативу данному методу можно пользоваться опцией компилятора nvcc --use_fast_math | -use_fast_math (использовать библиотеку быстрых, но не точных вычислений), которая автоматически при выполнении всех математических операций заменяет их на более быстрые аналоги, что дает прирост производительности, но и все связанные с этим недостатки. Мы предлагаем пользоваться данным методом при планировании ожидаемого выигрыша от реорганизации вычислений.
1.6 Исследование производительности
Одной из целей данной работы является создание более производительного метода вейвлет преобразования сигнала, чтобы впоследствии рассмотреть возможность применения в интерактивных методах множества прикладных областей (от исследований сейсмических сигналов до сжатия изображений).
На рисунке ниже приведен результат преобразования на основе GPGPU, как можно заметить мы достигли некоторого шумоподавления обусловленного применением вейвлета Добеши 8.
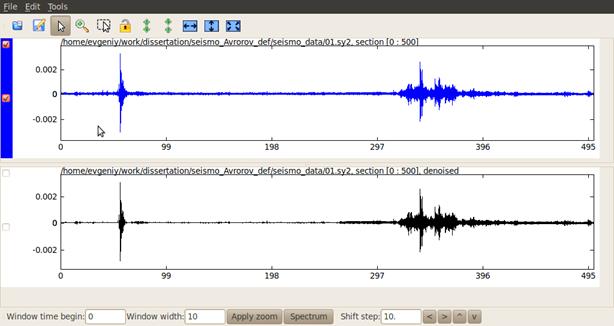
Рисунок 12 – Вейвлет фильтрация сейсмического сигнала
Для исследования производительности немного провести серию тестов на разных объемах входных данных. Заметим, что трудоемкость работы метода не зависит от характера входных данных, а только от их объема. Чтобы сориентироваться в достигнутом на данный момент быстродействии вейвлет преобразования будем тестировать одновременно и последовательный метод вейвлет преобразования для CPU, взятый из промышленной свободно распространяемой библиотеки gsl. В таблицах 3 и 4 приведены конфигурации тестовой системы.
В приложении В отражен запуск теста вейвлет преобразования для разных объемов входных данных. В таблице ниже и на графике приведены времена преобразований для CPU и для GPU.
Таблица 2 — Время на Вейвлет фильтрацию
| Количество отсчетов
|
CPU преобразование, мс
|
CUDA преобразование, мс
|
CUDA в сравнении с CPU, раз
|
| 65536
|
12
|
67
|
0,18
|
| 131072
|
26
|
67
|
0,39
|
| 262144
|
81
|
61
|
1,33
|
| 524288
|
159
|
73
|
2,18
|
| 1048576
|
319
|
85
|
3,75
|
| 2097152
|
677
|
97
|
6,98
|
| 4194304
|
1401
|
133
|
10,53
|
| 8388608
|
2855
|
209
|
13,66
|
| 16777216
|
5964
|
355
|
16,80
|
| 33554432
|
11979
|
638
|
18,78
|
| 67108864
|
31802
|
1350
|
23,56
|
Как и ожидалось, время на процессоре растет линейно при росте объемов входных данных, а на GPGPU близка к константе.
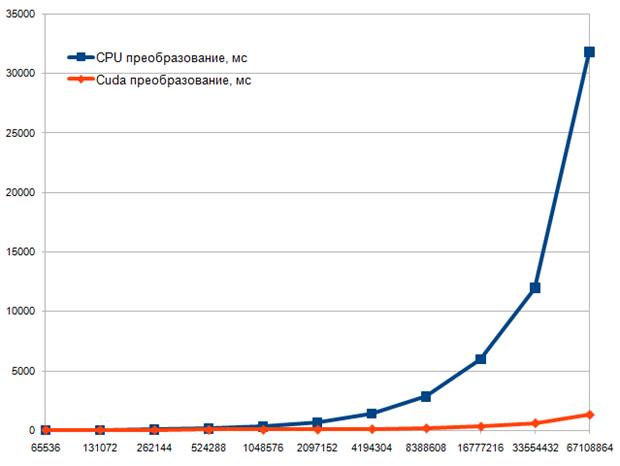
Рисунок 13 — Время вейвлет преобразования сигнала
Таблица 3 ‑ Аппаратная часть тестовой платформы
| Центральный процессор:
|
Intel Core 2 Duo E2200 2.2 ГГц 2 Мб Cache;
частота шины 800 МГц;
|
| Оперативная память:
|
2048 Мб DDR3 800 МГц;
|
| Чипсет:
|
Intel G33;
|
| Видеоадаптер:
|
Дискретный стоковый адаптер NVidia Corporation;
NVIDIA GeForce 9800 GT 1024 Мб GDDR-3;
|
Таблица 4 ‑ Программная часть тестовой платформы
| Операционная система
|
Ubuntu Linux 10.04 x86 32бит;
|
| Драйвер
|
NVIDIA Driver for Linux 195.35.08 ;
|
| Версия CUDA SDK
|
CUDA SDK 3.0 for Linux
|
| Версия CUDA toolkit
|
CUDA Toolkit 3.0 for Linux
|
Заключение
В результате выполнения данной работы были достигнуты поставленные цели.
· Разработан модуль вейвлет преобразования на основе GPGPU.
· Исследована производительность модуля, время выполнения на GPGPU NVIDIA 9800 GT в сравнении с CPU Intel Core 2 DUO E2200 в 23 раза меньше.
· Модуль поддерживает вейвлет преобразование для всех распространенных материнских вейвлетов.
· Модуль внедрен в действующий программный комплекс по анализу сейсмических сигналов Seismo Detector.
· Исследована практическая эффективность Cuda технологии для решения многопроходных задач, допускающих мелкозернистый параллелизм.
Как развитие данной работы планируется разработка гетерогенных вычислительных методов, которые будут использовать и универсальные процессоры и специализированные параллельно массивные вычислители GPGPU совместно для решения задач, что в целом при работе в ограниченных условиях (полевых, или ограниченных бюджетных условиях) даст существенное преимущество в скорости работы.
Список использованных источник
ов
1. Хайретдинов М.С., Клименко С.М. Программная система автоматизированной локации и визуализации сейсмических источников. Труды III Межд. конф. "Мониторинг ядерных испытаний и их последствий", Боровое, 2004.–Вестник НЯЦ РК, С.70–76
2. NVIDIA CUDA Programming Guide / NVIDIA Corporation, 2008 – 111 с.
3. Luebke, D., GPGPU: General Purpose Computation On Graphics Hardware / Luebke D., Harris M., Kruger J., и др. – SIGGRAPH, 2005. – 277 c
4. Tarditi, D.Accelerator: Using Data Parallelism to Program GPUs for General-Purpose Uses / Tarditi D., Puri S., Oglesby J – Microsoft Research, 2006 – 11 с.
Приложение А. Исходный код Вейвлет преобразования на GPGPU
dwt_kernel_float.cu — ядра
GPGPU
#ifndef _DWT_KERNEL_H_
#define _DWT_KERNEL_H_
#include <stdio.h>
#include "dwt_float.h"
__global__ void
cudaDWTStepForward(float *a, const size_t n, const size_t nmod/*, const size_t stride*/, const float * const h1, const float* const g1, const size_t nc, float*scratch)
{
__shared__ float sh_h1[NC_SZ]; // h1 в общей памяти
__shared__ float sh_g1[NC_SZ]; // h2 в общей памяти
const size_t tidx = threadIdx.x;
if(tidx < nc){ // загружаем коэффициенты в общую память их у нас nc
sh_h1[tidx] = h1[tidx]; // выполняя все потоки блока мы заполняем общую память для блока
sh_g1[tidx] = g1[tidx]; //
}
const size_t idbx = (blockDim.x - nc) * blockIdx.x; // индекс данных соответствующих началу блока
__shared__ float sh_ai[2*BL_SZ]; // включает nc/2 элементов перед + (blockDim.x - nc/2) нормальных элементов.
const int a_idx = idbx + tidx; //индекс текущего элемента данных
const size_t ni = 2*a_idx + nmod;
if( ni >= n) { // имитируем заполнение нулями несуществующих предыдущих элементов
sh_ai[2*tidx] = 0.0f;
sh_ai[2*tidx + 1] = 0.0f;
} else { // заполняем нужными значениями
sh_ai[2*tidx] = a[ni];
sh_ai[2*tidx + 1] = a[ni + 1];
}
__syncthreads(); // синхронизация потоков для нормальности общей регистровой памяти памяти
const size_t nh = n>>1;
if(a_idx < nh && tidx < blockDim.x - nc){ //
float h = 0, g = 0;
for (size_t k = 0; k < nc; k++) // работа с коэффициентами
{
// const size_t jf = n1 & (ni + k);
// const float ani = a[stride * jf];
const float ani = sh_ai[2*tidx + k];
h += sh_h1[k] * ani;
g += sh_g1[k] * ani;
}
scratch[a_idx] = h; // Преобразованные данные
scratch[a_idx + n/2] = g;
}
}
// Сделать шаг обратной фильтрации - сейчас прямая
__global__ void
cudaDWTStepBack(float *a, const size_t n, const size_t nmod, const size_t stride, const float * const h2, const float* const g2, const size_t nc, float*scratch)
{ // 128 сильно зависит от nc и количество обрабатываемых данных в одном блоке при слиянии
__shared__ float sh_h2[NC_SZ]; // nc коэффициентов
__shared__ float sh_g2[NC_SZ]; // nc коэффициентов
const size_t tidx = threadIdx.x; // индекс потока
// if(tidx < 2*nc){ // проверить вероятно лишнее
if(tidx < nc){ // загружаем коэффициенты в общую память их у нас nc
sh_h2[tidx] = h2[tidx];
sh_g2[tidx] = g2[tidx];
}
const size_t nc_div_2 = nc/2;
const size_t idbx = (blockDim.x - nc_div_2) * blockIdx.x; // индекс данных соответствующих началу блока
const int a_idx = idbx + (tidx - nc_div_2); //индекс текущего элемента данных
__shared__ float sh_ai[BL_SZ]; // включает nc/2 элементов перед + (blockDim.x - nc/2) нормальных элементов.
__shared__ float sh_ai1[BL_SZ]; // то же самое, но из второй половины
const size_t nh = n>>1;
if(a_idx < nh){ // работаем только с нужным диапозоном
if( a_idx < 0) { // имитируем заполнение нулями несуществующих предыдущих элементов
sh_ai[tidx] = 0.0f;
sh_ai1[tidx] = 0.0f;
} else { // заполняем нужными значениями
sh_ai[tidx] = a[a_idx];
sh_ai1[tidx] = a[a_idx + nh];
}
}
__syncthreads(); // синхронизация потоков для нормальности общей регистровой памяти
// Здесь выполняем работу по слиянию
if(a_idx < nh && tidx >= nc_div_2){ // работаем с потоками больше nc/2, и в нужном диапозоне данных
float ai;
float ai1;
float s = 0.0f;
float s2 = 0.0f;
for (size_t k = 0, k_div_2 = 0; k < nc; k+=2, k_div_2++) { // вычисление четного и нечетного членов при слиянии
ai = sh_ai[tidx - k_div_2];
ai1 = sh_ai1[tidx - k_div_2];
s += ai*sh_h2[k] + ai1*sh_g2[k]; // для четных элементов
s2 += ai*sh_h2[k + 1] + ai1*sh_g2[k + 1]; // для нечетных элементов
}
const size_t ni = (n - 1)&(2*a_idx + nmod);
scratch[ni] = s;
scratch[ni + 1] = s2;
}
// }
}
__global__ void
cudaDenoiseKernel(float *data, const size_t n,const float threshold)
{
const size_t idx = blockDim.x * blockIdx.x + threadIdx.x; // индекс элемента данных в первой половине = РазмерБлока*номерБлока + индексПотокаВБлоке
if(idx < n){
float d = data[idx];
const float fd = fabsf(d);
float t = fd - threshold;
t = (t + fabsf(t)) / 2.f;
// Signum
if (d != 0.f) d = d / fd * t;
data[idx] = d;
// tmp[idx] = t;
}
}
#endif
dwt_float.cu — промежуточный слой между CPU и GPU слоями
// Utilities and system includes
#include <shrUtils.h>
#include "cutil_inline.h"
#include "dwt_float.h" // Загрузка объявлений функций ядер и их параметров
void initGPUDevice()
{
cudaSetDevice(cutGetMaxGflopsDeviceId());
}
void exitGPUDevice()
{
cudaThreadExit();
}
// перед запуском нужно еще инициализировать адаптер где-то
void cudaDStepForward(float *a, float *d_a, const size_t n, const size_t nmod, const size_t stride, const float * const d_h1, const float* const d_g1, const size_t nc, float*d_scratch)
{
// Выделение памяти на видео-карте под данные и коэффициенты
cutilSafeCall(cudaMemcpy(d_a, a, sizeof(*a)*n,
cudaMemcpyHostToDevice) );
// параметры конфигурации исполнения
const size_t block_size = BL_SZ;
dim3 threads( block_size, 1);
const size_t grid_size = (n/2) / (block_size - nc) + (((n/2)%(block_size - nc))>0); // n/2 потому проходится лишь первая половина
dim3 grid(grid_size, 1);
// запуск ядра на видео-карте
cudaDWTStepForward<<< grid, threads >>>(d_a, n, nmod/*, stride*/, d_h1, d_g1, nc, d_scratch);
// Сохранение обработанных данных в память хоста
cutilSafeCall(cudaMemcpy( a, d_scratch, sizeof(*a)*n,
cudaMemcpyDeviceToHost) );
// Выйти из всех потоков
cudaThreadExit();
}
// перед запуском нужно еще инициализировать адаптер где-то
void cudaDStepInverse(float *a, float *d_a, const size_t n, const size_t nmod, const size_t stride, const float * const d_h2, const float* const d_g2, const size_t nc, float*d_scratch)
{
// Выделение памяти на видео-карте под данные и коэффициенты
cutilSafeCall(cudaMemcpy(d_a, a, sizeof(*a)*n,
cudaMemcpyHostToDevice) );
// параметры конфигурации исполнения
const size_t block_size = 512;
dim3 threads( block_size, 1);
const size_t grid_size = (n/2) / (block_size - nc/2) + (((n/2)%(block_size - nc/2))>0); // n/2 потому проходится лишь первая половина
dim3 grid(grid_size, 1);
// запуск ядра на видео-карте
cudaDWTStepBack<<< grid, threads >>>(d_a, n, nmod, stride, d_h2, d_g2, nc, d_scratch);
cudaThreadSynchronize(); // синхронизация потоков выполнения на видеокарте
// Сохранение обработанных данных в память хоста
cutilSafeCall(cudaMemcpy( a, d_scratch, sizeof(*a)*n, cudaMemcpyDeviceToHost) );
// Выйти из всех потоков
cudaThreadExit();
}
#define ELEMENT(a,stride,i) ((a)[(stride)*(i)])
void
cudaDwtStepDevice (const gsl_wavelet_float * w, float *a, float *d_a, size_t stride, size_t n,
gsl_wavelet_direction dir, gsl_wavelet_workspace_float * work, float * d_h, float* d_g, float* d_scratch)
{
size_t nmod;
nmod = w->nc * n ;
nmod -= w->offset; // center support
if (dir == gsl_wavelet_forward)
{ // прямое преобразование
cudaDStepForward(a, d_a, n, nmod, stride, d_h, d_g, w->nc, d_scratch);
}
else
{ // обратное преобразование
cudaDStepInverse(a, d_a, n, nmod, stride, d_h, d_g, w->nc, d_scratch);
}
}
void
cudaDwtTransform (const gsl_wavelet_float * w, float *data, size_t stride, size_t n,
gsl_wavelet_direction dir, gsl_wavelet_workspace_float * work){
float* d_a;
cutilSafeCall(cudaMalloc((void**) &d_a, sizeof(*data)*n));
cutilSafeCall(cudaMemcpy(d_a, data, sizeof(*data)*n,
cudaMemcpyHostToDevice) );
float* d_scratch;
cutilSafeCall(cudaMalloc((void**) &d_scratch, sizeof(*data)*n));
int i;
if (dir == gsl_wavelet_forward)
{
float* d_h1;
cutilSafeCall(cudaMalloc((void**) &d_h1, sizeof(*w->h1)*w->nc));
cutilSafeCall(cudaMemcpy(d_h1, w->h1, sizeof(*w->h1)*w->nc,
cudaMemcpyHostToDevice) );
float* d_g1;
cutilSafeCall(cudaMalloc((void**) &d_g1, sizeof(*w->g1)*w->nc));
cutilSafeCall(cudaMemcpy(d_g1, w->g1, sizeof(*w->g1)*w->nc,
cudaMemcpyHostToDevice) );
for (i = n; i >= 2; i >>= 1)
{
cudaDwtStepDevice (w, data, d_a, stride, i, dir, work, d_h1, d_g1, d_scratch);
}
cutilSafeCall(cudaFree(d_h1));
cutilSafeCall(cudaFree(d_g1));
}
else
{
float* d_h2;
cutilSafeCall(cudaMalloc((void**) &d_h2, sizeof(*w->h2)*w->nc));
cutilSafeCall(cudaMemcpy(d_h2, w->h2, sizeof(*w->h2)*w->nc,
cudaMemcpyHostToDevice) );
float* d_g2;
cutilSafeCall(cudaMalloc((void**) &d_g2, sizeof(*w->g2)*w->nc));
cutilSafeCall(cudaMemcpy(d_g2, w->g2, sizeof(*w->g2)*w->nc,
cudaMemcpyHostToDevice) );
for (i = 2; i <= n; i <<= 1)
{
cudaDwtStepDevice (w, data, d_a, stride, i, dir, work, d_h2, d_g2, d_scratch);
}
cutilSafeCall(cudaFree(d_h2));
cutilSafeCall(cudaFree(d_g2));
}
cutilSafeCall(cudaMemcpy( work->scratch, d_scratch, sizeof(*d_scratch)*n,
cudaMemcpyDeviceToHost) );
cutilSafeCall(cudaMemcpy( data, d_a, sizeof(*d_a)*n,
cudaMemcpyDeviceToHost) );
cutilSafeCall(cudaFree(d_scratch));
cutilSafeCall(cudaFree(d_a));
}
void cudaDenoise(float* data, const int len, const float threshold) // Функция самой фильтрации
{
float* d_a;
cutilSafeCall(cudaMalloc((void**) &d_a, sizeof(*data)*len));
cutilSafeCall(cudaMemcpy(d_a, data, sizeof(*data)*len,
cudaMemcpyHostToDevice) );
// параметры конфигурации исполнения
const size_t block_size = 16;
dim3 threads( block_size, 1);
const size_t grid_size = len / (block_size) + ((len%(block_size))>0); // n/2 потому проходится лишь первая половина
dim3 grid(grid_size, 1);
// запуск ядра на видео-карте
cudaDenoiseKernel<<< grid, threads >>>(d_a, len, threshold);
cudaThreadSynchronize(); // синхронизация потоков выполнения на видеокарте
cutilSafeCall(cudaMemcpy( data, d_a, sizeof(*data)*len, cudaMemcpyDeviceToHost) );
cutilSafeCall(cudaFree(d_a));
}
dwt_float.h — заголовочный файл с описание ядер и их параметров
extern "C" void initGPUDevice();
extern "C" void exitGPUDevice();
__global__ void
cudaDWTStep(float *a, const size_t n, const size_t nmod/*, const size_t stride*/, const float * const h1, const float* const g1, const size_t nc, float*scratch);
__global__ void
cudaDWTStepForward(float *a, const size_t n, const size_t nmod/*, const size_t stride*/, const float * const h1, const float* const g1, const size_t nc, float*scratch);
// Сделать шаг обратной фильтрации - сейчас прямая
__global__ void
cudaDWTStepBack(float *a, const size_t n, const size_t nmod, const size_t stride, const float * const h1, const float* const g1, const size_t nc, float*scratch);
#include "wavelet/gsl_wavelet.h"
extern "C" void
cudaDwtTransform (const gsl_wavelet_float * w, float *a, size_t stride, size_t n,
gsl_wavelet_direction dir, gsl_wavelet_workspace_float * work);
__global__ void
cudaDenoiseKernel(float *data, const size_t n, float threshold);
extern "C" void cudaDenoise(float* data, int len, float threshold);
#define NC_SZ 128
#define BL_SZ 256
wavelet_denoise.cpp – общий ход Вейвлет преобразования
int cuda_wavelet_denoise_auto(double* data, int len) // must work on GPGPU
{
float* floatdata = (float*) malloc(len * sizeof(float));
/* Объявление переменных */
double* threshold_rescales; /* Массив масштабов порогов для каждого из уровней разложения */
gsl_wavelet *wavelet; /* Структура представления вейвлета */
gsl_wavelet_workspace *work; /* Служебная структура для промежуточных данных */
gsl_wavelet_float waveletfloat; /* Структура представления вейвлета */
gsl_wavelet_workspace_float workfloat; /* Служебная структура для промежуточных данных */
int decomp_level; /* Уровень дискретного вейвлет-разложения */
double threshold; /* Порог для пороговой обработки коэффициентов */
double thresh_curr; /* Значение порога, смасштабированное для конкретного уровня разложения */
double len_curr; /* Длина отрезка массива коэеффициентов для конкретного уровня разложения */
int k; /* Счётчик цикла */
int i;
/* Инициализация переменных */
decomp_level = get_power_of_2(len); /* Вычисление уровня вейвлет-разложения */
if (decomp_level == -1) return -2; /* TODO: код ошибки: "массив данных имеет длину не равную степени 2-ки" */
threshold_rescales = (double*) malloc(decomp_level * sizeof(double));
if (threshold_rescales == 0) return -1; //TODO: код ошибки: "Не достаточно памяти"
wavelet = gsl_wavelet_alloc (gsl_wavelet_daubechies, 8);
work = gsl_wavelet_workspace_alloc (len);
waveletfloat.nc = wavelet->nc;
waveletfloat.type = wavelet->type;
waveletfloat.offset = wavelet->offset;
waveletfloat.g1 = (float*)malloc(wavelet->nc*sizeof(float));
waveletfloat.g2 = (float*)malloc(wavelet->nc*sizeof(float));
waveletfloat.h1 = (float*)malloc(wavelet->nc*sizeof(float));
waveletfloat.h2 = (float*)malloc(wavelet->nc*sizeof(float));
doubleCopyToFloat(wavelet->g1, (float*)waveletfloat.g1, wavelet->nc);
doubleCopyToFloat(wavelet->g2, (float*)waveletfloat.g2, wavelet->nc);
doubleCopyToFloat(wavelet->h1, (float*)waveletfloat.h1, wavelet->nc);
doubleCopyToFloat(wavelet->h2, (float*)waveletfloat.h2, wavelet->nc);
workfloat.n = work->n;
workfloat.scratch = (float*)malloc(sizeof(float)*work->n);
doubleCopyToFloat(work->scratch, workfloat.scratch, work->n);
initGPUDevice();
QTime FullFilterTime;
FullFilterTime.start();
/* Прямое вейвлет-преобразование */
doubleCopyToFloat(data, floatdata, len);
cudaWaveletTransform_forward (&waveletfloat, floatdata, 1, len, &workfloat);
/* ----------------------------------------- */
/* Начало фильтрации */
noise_estimation_float(floatdata, threshold_rescales, decomp_level); /* Вычисление масштабных коэфф-в для каждого уровня разложения */
threshold = select_threshold(len); /* Оценка значения базового порога */
i = len / 2;
len_curr = len / 2;
for (k = decomp_level - 1; k >= 0; k--)
{
thresh_curr = threshold * threshold_rescales[decomp_level - 1 - k];
cudaDenoise( &(floatdata[i]), len_curr, (float)thresh_curr);
len_curr /= 2;
i -= len_curr;
}
/* Конец фильтрации */
/* ----------------------------------------- */
/* Обратное вейвлет-преобразование (восстановление сигнала) */
cudaWaveletTransform_inverse (&waveletfloat, floatdata, 1, len, &workfloat);
floatCopyToDouble(floatdata, data, len);
exitGPUDevice();
qDebug("Cuda FullFilterTime: %d ms", FullFilterTime.elapsed());
free((void*)waveletfloat.g1);
free((void*)waveletfloat.g2);
free((void*)waveletfloat.h1);
free((void*)waveletfloat.h2);
free((void*)workfloat.scratch);
free (threshold_rescales);
gsl_wavelet_free (wavelet);
gsl_wavelet_workspace_free (work);
return 0;
}
Приложение Б. Характеристики сопроцессора на основе GPGPU
evgeniy@evgeniy-desktop:~/NVIDIA_GPU_Computing_SDK/C/bin/linux/release$ sudo ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
There is 1 device supporting CUDA
Device 0: "GeForce 9800 GT"
CUDA Driver Version: 3.0
CUDA Runtime Version: 3.0
CUDA Capability Major revision number: 1
CUDA Capability Minor revision number: 1
Total amount of global memory: 1073020928 bytes
Number of multiprocessors: 14
Number of cores: 112
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 16384 bytes
Total number of registers available per block: 8192
Warp size: 32
Maximum number of threads per block: 512
Maximum sizes of each dimension of a block: 512 x 512 x 64
Maximum sizes of each dimension of a grid: 65535 x 65535 x 1
Maximum memory pitch: 2147483647 bytes
Texture alignment: 256 bytes
Clock rate: 1.50 GHz
Concurrent copy and execution: Yes
Run time limit on kernels: Yes
Integrated: No
Support host page-locked memory mapping: No
Compute mode: Default (multiple host threads can use this device simultaneously)
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 134564823, CUDA Runtime Version = 3.0, NumDevs = 1, Device = GeForce 9800 GT
Приложение В. Запуск теста вейвлет преобразования
evgeniy@evgeniy-desktop:~/work/dissertation/seismo_source/seismo_detector$ ./seismodetector
sample count: 65536
CPU FullFilterTime: 12 ms
Cuda FullFilterTime: 67 ms
sample count: 131072
CPU FullFilterTime: 26 ms
Cuda FullFilterTime: 67 ms
sample count: 262144
CPU FullFilterTime: 81 ms
Cuda FullFilterTime: 61 ms
sample count: 524288
CPU FullFilterTime: 159 ms
Cuda FullFilterTime: 73 ms
sample count: 1048576
CPU FullFilterTime: 319 ms
Cuda FullFilterTime: 85 ms
sample count: 2097152
CPU FullFilterTime: 677 ms
Cuda FullFilterTime: 97 ms
sample count: 4194304
CPU FullFilterTime: 1401 ms
Cuda FullFilterTime: 133 ms
sample count: 8388608
CPU FullFilterTime: 2855 ms
Cuda FullFilterTime: 209 ms
sample count: 16777216
CPU FullFilterTime: 5964 ms
Cuda FullFilterTime: 355 ms
sample count: 33554432
CPU FullFilterTime: 11979 ms
Cuda FullFilterTime: 638 ms
sample count: 67108864
CPU FullFilterTime: 31802 ms
Cuda FullFilterTime: 1350 ms
|

