В конце второго тысячелетия человечество шагнуло из индустриальной эры в эру информационную. Если раньше главными были материальные ресурсы и рабочая сила, то теперь решающими факторами развития общества становятся интеллект и доступ к информации. В информационном обществе люди в основном будут заняты в сфере создания, распределения и обмена информации, а каждый человек сможет получить необходимые продукт или услугу в любом месте и в любое время.
По направлению к базам данных
Как известно, основной инструмент хранения и переработки информации - электронные вычислительные машины (ЭВМ). Переход к информационному обществу сопровождается лавинообразным ростом объемов информации, хранимой в них. Это в свою очередь порождает проблему эффективной организации и поиска информации. Для представления в машинах больших объемов данных используются технологии баз данных. База данных представляет собой совокупность структурированных и взаимосвязанных данных, хранимых более или менее постоянно в ЭВМ на магнитных (пока) носителях, и используемых одновременно многими пользователями в рамках некоторого предприятия, организации или сообщества. Для работы с базами данных используется специальное системное программное обеспечение, называемое СУБД (Система управления базами данных). Вычислительный комплекс, включающий в себя соответствующую аппаратуру (ЭВМ с устройствами хранения) и работающий под управлением СУБД, называется машиной баз данных.
Первые такие машины появились во второй половине 60-х годов ушедшего века. В настоящее время на рынок программного обеспечения поставляются сотни различных коммерческих СУБД практически для всех моделей ЭВМ. До недавнего времени большинство машин баз данных включали в себя только один процессор. Однако в последнее десятилетие возник целый ряд задач, требующих хранения и обработки сверхбольших объемов данных. Один из наиболее впечатляющих примеров решения задач такого типа - создание базы данных Системы наблюдения Земли. Эта система (Earth Observing System, EOS) включает в себя множество спутников, которые собирают информацию, необходимую для изучения долгосрочных тенденций состояния атмосферы, океанов, земной поверхности. Спутники поставляют на Землю 1/3 петабайт информации в год (petabyte - 1015
байт), что сопоставимо с объемом информации (в кодах ASCII), хранящейся в Российской государственной библиотеке. Полученная со спутников, она накапливается в базе данных EOSDIS (EOS Data and Information System) невиданных прежде размеров.
Другая грандиозная задача, тоже требующая использования сверхбольших баз данных, ставится в проекте создания Виртуальной астрономической обсерватории. Такая обсерватория должна объединить данные, получаемые всеми обсерваториями мира в результате наблюдения звездного неба; объем этой базы составит десятки петабайт. Очевидно, даже самые мощные однопроцессорные ЭВМ не справятся с обработкой этого потока.
Забиваем Сайты В ТОП КУВАЛДОЙ - Уникальные возможности от SeoHammer
Каждая ссылка анализируется по трем пакетам оценки: SEO, Трафик и SMM.
SeoHammer делает продвижение сайта прозрачным и простым занятием.
Ссылки, вечные ссылки, статьи, упоминания, пресс-релизы - используйте по максимуму потенциал SeoHammer для продвижения вашего сайта.
Что умеет делать SeoHammer
— Продвижение в один клик, интеллектуальный подбор запросов, покупка самых лучших ссылок с высокой степенью качества у лучших бирж ссылок.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз,
а первые результаты появляются уже в течение первых 7 дней.
Зарегистрироваться и Начать продвижение
Естественное решение проблемы обработки сверхбольших баз данных - использовать в качестве машин баз данных многопроцессорные ЭВМ, позволяющие организовать параллельную обработку информации. Интенсивные исследования в области параллельных машин были начаты в 80-х годах. В течение последних двух десятилетий такие машины проделали путь от экзотических экспериментальных прототипов, разрабатываемых в научно-исследовательских лабораториях, к полнофункциональным коммерческим продуктам, поставляемым на рынок высокопроизводительных информационных систем.
В качестве примеров успешных коммерческих проектов создания параллельных систем баз данных можно назвать DB2 Parallel Edition [1], NonStop SQL [2] и NCR Teradata [3]. Подобные системы объединяют до тысячи процессоров и магнитных дисков и способны обрабатывать базы данных в десятки терабайт. Тем не менее и в настоящее время здесь остается ряд проблем, требующих дополнительных научных изысканий. Одно из них - дальнейшее развитие аппаратной архитектуры параллельных машин. Как указывается в Асиломарском отчете о направлениях исследований в области баз данных [4], в ближайшее время крупные организации будут располагать базами данных объемом в несколько петабайт. Для обработки подобных объемов информации потребуются параллельные машины с десятками тысяч процессоров, что в сотни раз превышает их число в современных системах. Однако традиционные архитектуры параллельных машин баз данных вряд ли допускают простое масштабирование на два порядка величины.
Сила и слабость параллельных систем
В основе современной технологии систем баз данных лежит реляционная модель, предложенная Е.Ф.Коддом еще в 1969 г. [5]. Первые реляционные системы появились на рынке в 1983 г., а сейчас они прочно заняли доминирующее положение. Реляционная база данных состоит из отношений, которые легче всего представить себе в виде двумерных (плоских) таблиц, содержащих информацию о некоторых классах объектов из предметной области. В случае базы данных, хранящей список телефонных номеров, таким классом объектов будут абоненты городской телефонной сети. Каждая таблица состоит из набора однородных записей, называемых кортежами. Все кортежи в отношении содержат один и тот же набор атрибутов, которые можно рассматривать как столбцы таблицы. Атрибуты представляют свойства конкретных экземпляров объектов определенного класса. Примерами атрибутов отношения Телефонная_книга
могут служить Фамилия, Номер, Адрес
. Совокупность отношений и образует базу данных, которая в виде файлов специального формата хранится на магнитных дисках или других устройствах внешней памяти.
Сервис онлайн-записи на собственном Telegram-боте
Попробуйте сервис онлайн-записи VisitTime на основе вашего собственного Telegram-бота:
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно.
Зарегистрироваться в сервисе
Над реляционными отношениями определен набор операций, образующих реляционную алгебру. Аргументами и результатами реляционных операций являются отношения. Запросы к реляционным базам данных формулируются на специальном языке запросов SQL (ранее называемом SEQUEL) [6]. На рис.1 показан пример запроса на языке SQL, выполняющего операции селекции и проекции. В нашем случае из отношения Телефонный_справочник
осуществляется выборка (селекция) всех записей, у которых атрибут Фамилия принимает значение ‘Иванов’.
В результирующее отношение проецируются только столбцы Номер и Адрес.

Рис.1.
Пример запроса на языке SQL, выбирающего из отношения Телефонная_книга
номера телефонов и адреса всех абонентов с фамилией Иванов.
Если исходное отношение достаточно велико, выполнение операции селекции скорее всего потребует значительных затрат машинного времени. Для ускорения мы можем попытаться организовать параллельное выполнение запроса на нескольких процессорных узлах многопроцессорной системы. К счастью, реляционная модель наилучшим образом подходит для “распараллеливания” запросов. В самой общей форме этот процесс можно описать так. Каждое отношение делится на фрагменты, которые располагаются на различных дисковых устройствах. Запрос применяется не к отношению в целом, а к данным фрагментам. Каждый фрагмент обрабатывается на отдельном процессоре. Результаты, полученные на различных процессорах, затем объединяются (сливаются) в общее результирующее отношение, как это схематично показано на рис.2. Таким образом, разбивая отношение на n фрагментов в параллельной машине баз данных с n
процессорными узлами, мы уменьшаем время выполнения запроса в n
раз!
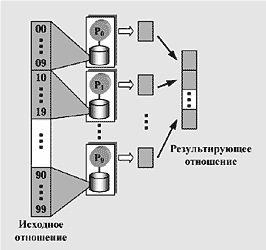
Рис.2.
Параллельное выполнение запроса. Исходное отношение разбивается на фрагменты по первым двум цифрам телефонного номера. Каждый фрагмент имеет свои собственные диск для хранения и процессор для обработки. Результирующее отношение объединяет данные, поставляемые отдельными узлами системы.
Однако не все так просто, как может показаться сначала. Первая проблема, с которой мы столкнемся, - по какому критерию производить деление отношения на фрагменты? В нашем примере на рис.2 мы применили так называемое упорядоченное разделение, использующее первые две цифры телефонного номера в качестве критерия распределения кортежей по дискам. Но подобный способ разбиения отнюдь не идеален, так как в результате мы скорее всего получим фрагменты, существенно различающиеся между собой по размерам, а это в свою очередь может привести к сильным перекосам в загрузке процессоров. При неудачной разбивке отношения на фрагменты на один из процессоров может выпасть более 50% от общего объема нагрузки, что снизит производительность нашей многопроцессорной системы до уровня системы с одним процессором!
Известно несколько методов разбиения отношения на фрагменты в параллельной машине баз данных (см., например, [7]), однако ни один из них не может обеспечить сбалансированной загрузки процессоров во всех случаях. Следовательно, чтобы “распараллеливание” запросов в параллельной машине стало эффективным, мы должны иметь некоторый механизм, позволяющий выполнять перераспределение (балансировку) нагрузки между процессорами динамически, т.е. непосредственно во время выполнения запроса.
Другая серьезная проблема, связанная с использованием параллельных машин баз данных, возникает из-за ограниченной масштабируемости. В многопроцессорной системе процессоры делят между собой некоторые аппаратные ресурсы: память, диски и соединительную сеть, связывающую отдельные процессоры между собой. Добавление каждого нового процессора приводит к замедлению работы других, использующих те же ресурсы. При большом числе участников может возникнуть ситуация, когда они будут дольше ждать того или иного общего ресурса, чем работать. В этом случае говорят об ограниченной масштабируемости системы.
Само число процессоров и дисков влечет за собой и третью серьезную проблему, с которой мы столкнемся при создании параллельных машин, - проблему обеспечения отказоустойчивости системы. Действительно, вероятность выхода из строя магнитного диска в однопроцессорной системе не очень велика. Однако, когда наша параллельная система включает в себя несколько тысяч процессоров и дисков, вероятность отказа возрастает в тысячи раз. Это рассуждение применимо к любой массовой аппаратной компоненте, входящей в состав многопроцессорной системы. Поэтому для параллельных машин баз данных проблема отказоустойчивости становится особенно важной.
Четвертая проблема связана с обеспечением высокой готовности данных: система должна восстанавливать потерянные данные таким образом, чтобы это было “не очень” заметно для пользователя, выполняющего запросы к базе данных. Если в процессе восстановления 80-90% ресурсов системы тратится исключительно на цели восстановления базы данных, то такая система может оказаться неприемлемой для случаев, когда ответ на запрос должен быть получен немедленно.
Как мы увидим в дальнейшем, подходы к решению указанных проблем в определяющей степени зависят от аппаратной архитектуры параллельной машины баз данных.
Архитектура бывает разная
В 1986 г. М.Стоунбрейкер [8], предложил разбить архитектуры параллельных машин баз данных на три класса: архитектуры с разделяемой памятью и дисками, архитектуры с разделяемыми дисками и архитектуры без совместного использования ресурсов (рис.3).
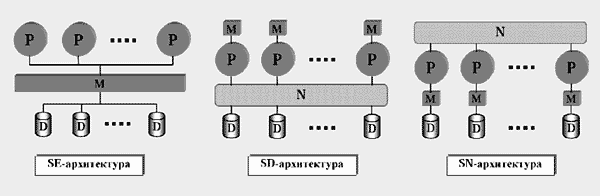
Рис.3.
Три классические архитектуры: SE-архитектура с разделяемой памятью и дисками, SD-архитектура с разделяемыми дисками, SN-архитектура без совместного использования ресурсов. В SE-системах все процессоры P с помощью общей шины подключаются к разделяемой памяти M и дискам D. Процессоры передают друг другу данные через общую память. В SD-системах каждый процессор имеет свою собственную память, однако диски по-прежнему разделяются всеми процессорами. Для связи процессоров друг с другом используется высокоскоростная соединительная сеть N. В SN-системах каждый процессор имеет собственную память и собственный диск. Обмен данными между процессорами, как и в предыдущем случае, происходит через высокоскоростную соединительную сеть.
В системах с разделяемой памятью и дисками все процессоры при помощи общей шины соединяются с разделяемой памятью и дисками. Обозначим такую архитектуру как SE (Shared-Everything). В SE-системах межпроцессорные коммуникации могут быть реализованы очень эффективно через разделяемую память. Поскольку здесь каждому процессору доступны вся память и любой диск, проблема балансировки загрузки процессоров не вызывает принципиальных трудностей (простаивающий процессор можно легко переключить с одного диска на другой). В силу этого SE-системы демонстрируют для небольших конфигураций (не превышающих 20 процессоров) более высокую производительность по сравнению с остальными архитектурами.
Однако SE-архитектура имеет ряд недостатков, самые неприятные из которых - ограниченная масштабируемость и низкая аппаратная отказоустойчивость. При большом количестве процессоров здесь начинаются конфликты доступа к разделяемой памяти, что может привести к серьезной деградации общей производительности системы (поэтому масштабируемость реальных SE-систем ограничивается 20-30 процессорами). Не могут обеспечить такие системы и высокую готовность данных при отказах аппаратуры. Выход из строя практически любой аппаратной компоненты фатален для всей системы. Действительно, отказ модуля памяти, шины доступа к памяти или шины ввода-вывода выводит из строя систему в целом. Что касается дисков, то обеспечение высокой готовности данных требует дублирования одних и тех же данных на разных дисках. Однако поддержание идентичности всех копий может существенным образом снизить общую производительность SE-системы в силу ограниченной пропускной способности шины ввода-вывода. Все это исключает использование SE-архитектуры в чистом виде для систем с высокими требованиями к готовности данных.
В системах с разделяемыми дисками каждый процессор имеет свою собственную память. Процессоры соединяются друг с другом и с дисковыми подсистемами высокоскоростной соединительной сетью. При этом любой процессор имеет доступ к любому диску. Обозначим такую архитектуру как SD (Shared-Disk). SD-архитектура по сравнению с SE-архитектурой демонстрирует лучшую масштабируемость и более высокую степень отказоустойчивости. Однако при реализации SD-систем возникает ряд серьезных технических проблем, которые не имеют эффективного решения. По мнению большинства специалистов, сегодня нет весомых причин для поддержки SD-архитектуры в чистом виде.
В системах без совместного использования ресурсов каждый процессор имеет собственную память и собственный диск. Процессоры соединяются друг с другом при помощи высокоскоростной соединительной сети. Обозначим такую архитектуру как SN (Shared-Nothing). SN-архитектура имеет наилучшие показатели по масштабируемости и отказоустойчивости. Но ничто не дается даром: основным ее недостатком становится сложность с обеспечением сбалансированной загрузки процессоров. Действительно, в SN-системе невозможно непосредственно переключить простаивающий процессор на обработку данных, хранящихся на “чужом” диске. Чтобы разгрузить некоторый процессорный узел, нам необходимо часть “необработанных” данных переместить по соединительной сети на другой, свободный узел. На практике это приводит к существенному падению общей эффективности системы из-за высокой стоимости пересылки больших объемов данных. Поэтому перекосы в распределении данных по процессорным узлам могут вызвать полную деградацию общей производительности SN-системы.
Иерархические архитектуры
Для преодоления недостатков, присущих SE- и SN-архитектурам, А.Бхайд в 1988 г. предложил рассматривать иерархические (гибридные) архитектуры [9], в которых SE-кластеры объединяются в единую SN-систему, как это показано на рис.4. SE-кластер представляет собой фактически самостоятельный мультипроцессор с разделяемой памятью и дисками. Между собой SE-кластеры соединяются с помощью высокоскоростной соединительной сети N. Обозначим такую архитектуру как CE (Clustered-Everything). Она обладает хорошей масштабируемостью, подобно SN-архитектуре, и позволяет достигать приемлемого баланса загрузки, подобно SE-архитектуре.
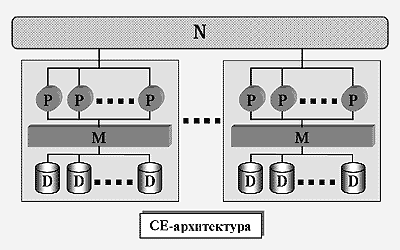
Рис.4.
CE-архитектура. Эта система объединяет несколько SE-кластеров с помощью высокоскоростной соединительной сети. Каждый отдельный кластер фактически представляет собой самостоятельный мультипроцессор с SE-архитектурой.
Основные недостатки CE-архитектуры кроются в потенциальных трудностях с обеспечением готовности данных при отказах аппаратуры на уровне SE-кластера. Для предотвращения потери данных из-за отказов необходимо дублировать одни и те же данные на разных SE-кластерах. Однако поддержка идентичности различных копий одних и тех же данных требует пересылки по соединительной сети значительных объемов информации. А это может существенным образом снизить общую производительность системы в режиме нормального функционирования и привести к тому, что SE-кластеры станут работать с производительностью, как у однопроцессорных конфигураций.
Чтобы избавиться от указанных недостатков, мы предложили [10] альтернативную трехуровневую иерархическую архитектуру (рис.5), в основе которой лежит понятие SD2-кластера. Такой кластер состоит из несимметричных двухпроцессорных модулей PM с разделяемой памятью и набора дисков, объединенных по схеме SD. Обозначим данную архитектуру как CD2 (Clustered-Disk with 2-processor modules).
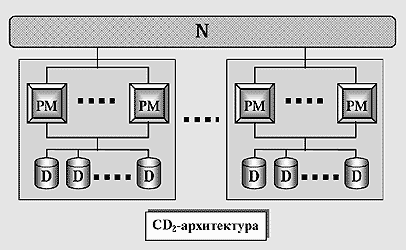
Рис.5.
CD2-архитектура. Система строится как набор SD2-кластеров, объединенных высокоскоростной соединительной сетью в стиле “без совместного использования ресурсов”. Каждый кластер – это система с разделяемыми дисками и двухпроцессорными модулями.
Структура процессорного модуля изображена на рис.6. Процессорный модуль имеет архитектуру с разделяемой памятью и включает в себя вычислительный и коммуникационный процессоры. Их взаимодействие осуществляется через общую оперативную память (RAM). Кроме этого, коммуникационный процессор имеет собственную память; он оснащен высокоскоростными внешними каналами (линками) для соединения с другими процессорными модулями. Его присутствие позволяет в значительной мере освободить вычислительный процессор от нагрузки, связанной с организацией передачи сообщений между процессорными узлами. Подобные процессорные модули выпускаются отечественной промышленностью для комплектования многопроцессорных вычислительных систем МВС-100/1000 [11].
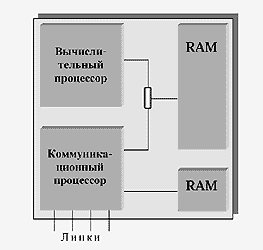
Рис.6.
Несимметричный двухпроцессорный модуль с разделяемой памятью. Модуль оснащен двумя процессорами, взаимодействующими через разделяемую память (RAM). Коммуникационный процессор имеет приватную память и оснащен высокоскоростными каналами (линками) для связи с другими модулями.
Такую CD2-архитектуру мы использовали при реализации прототипа параллельной системы управления данными “Омега” для отечественных многопроцессорных комплексов МВС-100/1000. Как показали эксперименты, CD2-система способна достичь общей производительности, сравнимой с производительностью CE-системы, даже при наличии сильных перекосов в распределении данных по дискам. В то же время CD2-архитектура позволяет обеспечить более высокую готовность данных, чем CE-архитектура.
А добиться этого помогли новые алгоритмы размещения данных и балансировки загрузки.
Как устроена система “Омега”
Иерархическая архитектура системы “Омега” предполагает два уровня фрагментации. Каждое отношение разделяется на фрагменты, размещаемые в различных SD2-кластерах (межкластерная фрагментация). В свою очередь каждый такой фрагмент дробится на еще более мелкие части, распределяемые по различным узлам SD2-кластера (внутрикластерная фрагментация). Данный подход делает процесс балансировки загрузки более гибким, поскольку он может выполняться на двух уровнях: локальном, среди процессорных модулей внутри SD2-кластера, и глобальном, среди самих SD2-кластеров.
В системе “Омега” диски, принадлежащие одному кластеру, на логическом уровне делятся на непересекающиеся подмножества физических дисков, каждое из которых образует так называемый виртуальный диск. Количество виртуальных дисков в SD2-кластере постоянно и совпадает с количеством процессорных модулей. В простейшем случае одному виртуальному диску соответствует один физический диск. Таким образом, на логическом уровне SD2-кластер может рассматриваться как система с SN-архитектурой, в то время как физически это система с SD-архитектурой.
В основе алгоритма балансировки загрузки лежит механизм репликации данных, названный внутрикластерным дублированием. Его суть в том, что каждый фрагмент отношения дублируется на всех виртуальных дисках кластера (далее для простоты мы будем опускать термин “виртуальный”).
Схема работы предлагаемого алгоритма балансировки загрузки иллюстрируется на примере кластера с двумя процессорами (рис.7). Здесь процессору P1
сопоставлен диск D1
, а процессору P2
- диск D2
. Предположим, что нам необходимо выполнить некоторую операцию, аргументом которой является отношение R. Мы делим фрагменты, на которые разбито отношение R внутри SD2-кластера, на две примерно равные части. Первая часть назначается для обработки процессору P1
, вторая - процессору P2
(на рис.7 данной стадии соответствует момент времени t0
).
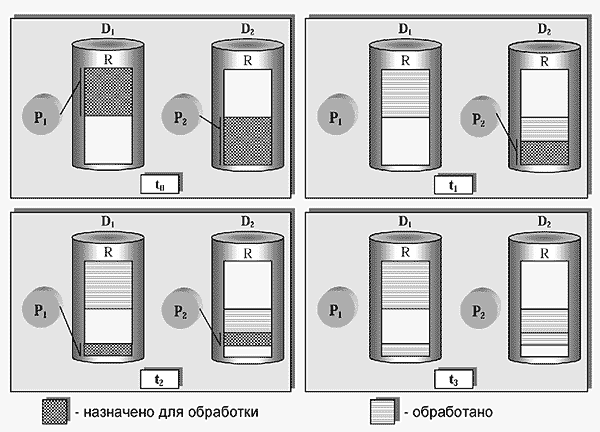
Рис.7.
Алгоритм балансировки загрузки для кластера с двумя процессорными узлами. На дисках D
1
и D
2
расположены две копии отношения R. Процессору P
1
разрешен доступ к копии, хранящейся на диске D
1
, а процессору P
2
– к копии на D
2
. В начальный момент времени t
0
фрагменты отношения R делятся между процессорами P
1
и P
2
примерно в равной пропорции. В момент времени t
1
процессор P
1
закончил обработку своей части отношения R, в то время как процессор P2 успел выполнить только половину назначенной ему работы. В момент времени t
2
происходит перераспределение необработанной части отношения R между двумя процессорами. Перераспределение продолжается до тех пор, пока отношение R не будет обработано полностью (момент времени t
3
).
В момент времени t1
процессор P1
закончил обработку своей части отношения R, в то время как процессор P2
успел выполнить только часть назначенной ему работы. В этом случае происходит повторное перераспределение необработанной части отношения R между двумя процессорами (момент времени t2
на рис.7). Процесс продолжается до тех пор, пока отношение R не будет полностью обработано (к моменту времени t3
). Алгоритм очевидным образом обобщается на произвольное число процессоров.
Предложенный алгоритм балансировки загрузки процессоров позволяет избежать перемещения по соединительной сети больших объемов данных. Это в конечном счете и обеспечивает такой системе производительность, сравнимую с производительностью SE-кластеров даже при наличии сильных перекосов данных.
Подведем итоги
Очевидно, что параллельные машины баз данных с одноуровневой архитектурой на сегодняшний день практически уже исчерпали ресурс дальнейшего эффективного масштабирования. На смену им приходят новые системы с иерархической архитектурой, которые могут включать в себя на два порядка больше процессоров и дисков.
Однако при построении иерархических систем по двухуровневому принципу, когда кластеры процессоров с разделяемой памятью и дисками объединяются в единую систему “без совместного использования ресурсов”, возникает проблема обеспечения высокой готовности данных в случае отказов аппаратуры. Действительно, при большом количестве кластеров в системе вероятность отказа одного из кластеров становится достаточно большой, и нам необходимо дублировать одни и те же данные на нескольких различных кластерах, что по существу сводит на нет все преимущества иерархической организации.
Поэтому следует ожидать, что дальнейшее развитие иерархических архитектур параллельных машин баз данных пойдет по пути создания многоуровневых гибридных схем, способных обеспечить высокую готовность данных на конфигурациях с несколькими сотнями тысяч процессорных узлов. В качестве прототипа таких систем предлагается параллельная система баз данных “Омега”, разрабатываемая в Челябинском государственном университете, которая имеет трехуровневую иерархическую архитектуру типа CD2 и может включать в себя сотни SD2-кластеров. Но оптимальную архитектуру SD2-кластера еще предстоит найти. Мы планируем испытать различные конфигурации SD2-кластеров, варьируя топологию межпроцессорных соединений, количество процессорных модулей, количество дисковых подсистем и количество дисков у отдельной дисковой подсистемы.
Работа выполнена при поддержке Российского фонда фундаментальных исследований. Проект 00-07-90077.
Литература
1. Игнатович Н.
// СУБД. 1997. №2. C.5-17.
2.Compaq NonStop SQL/MP. http://www.tandem.com/prod_des/nssqlpd/nssqlpd.htm
3. Лисянский К., Слободяников Д.
// СУБД. 1997. №5-6. C.25-46.
4. Бернштейн Ф. и др
. // Открытые системы. 1999. №1. C.61-68.
5. Кодд Е.Ф.
// СУБД. 1995. №1. C.145-169.
6. Чамберлин Д.Д. и др.
// СУБД. 1996. №1. C.144-159.
7. Девитт Д., Грэй Д.
// СУБД. 1995. №2. C.8-31.
8. Stonebraker M.
// Database Engineering Bulletin. March 1986. V.9. №1. P.4-9.
9. Bhide A.
An Analysis of Three Transaction Processing Architectures // Proceedings of 14-th Internat. Conf. on Very Large Data Bases (VLDB'88), 29 August - 1 September 1988. Los Angeles, California, USA, 1988. P.339-350.
10.Sokolinsky L.B., Axenov O., Gutova S.
Omega: The Highly Parallel Database System Project // Proceedings of the First East-European Symposium on Advances in Database and Information Systems (ADBIS’97), St.-Petersburg. September 2-5, 1997.V.2. P.88-90.
11.Левин В.К.
Отечественные суперкомпьютеры семейства МВС. http://parallel.ru/mvs/levin.html
|

